Abstract
StakeBaby (Skinny Bottle Ltd.) proposes a complete revamp of stakeglmr.com and stakemovr.com, to address limitations in the current code base. The new architecture will improve flexibility, expandability, and future-proof the design. The new platform will have faster load times, improved user experience, and an advanced staking interface that promotes diversification across multiple collators. The proposed setup will be cost-efficient, durable, and fast, using a two-layer approach for API durability and near-real-time performance at a lower operational cost.
Screenshot of custom UI components we have made for the new dashboard. This is just a template - not related to staking
Motivation
StakeBaby has supported over 100,000 unique Moonbeam and Moonriver users in making well-informed staking decisions by offering dependable and relevant data. This was achieved through self-funding and collation income. While this approach allowed us to serve the community, it led to a code base that is difficult to maintain and expand. As a result, we plan to replace the old code and develop a new system designed to 1) facilitate the addition of new features, and 2) enhance the overall staking experience.
Project Overview
Legacy project
Stakeglmr.com and stakemovr.com are currently Svelte SPAs with AWS Lambdas + DynamoDB on the backend. Chain data is currently indexed to a master DynamoDB table. The event stream of all INSERT operations is processed and triggers several Lambda microservices that update other tables in an idempotent manner. Although this setup is durable and has served us well, it poses limitations in upgradeability and expandability. Moreover, the code base has exploded with over 50 microservices and a largely patched frontend.
The new dashboard
StakeBaby plans to fully revamp the backend and frontend code for stakeglmr.com and stakemovr.com, upgrading both platforms to V2. The new architecture aims to be scalable, durable, leaner, and more flexible, enabling new features and an improved interface.
Faster load times - enhanced speed
The updated StakeGlmr and StakeMovr will load as quickly as standard apps, compared to the current 10-second load time. To achieve this, data will initially come from our API, with chain calls updating stale data as needed.
Expandable and flexible - improved design
The new architecture will use Subsquid to index the chain to a Postgres database, allowing for efficient creation and execution of various ETLs. This approach will enable quick re-implementation of existing features, easy extraction of more useful information, and a future-proof design.
Temporal.io will be used to manage ETL workflows, replacing the previous complex choreography and making it easier to adapt and expand. This design will ensure durability while allowing us to focus on business logic and value.
Less data, more information - streamlined interface
The collator dashboard will be simplified, offering users the option to access more details if desired. New features will include collator age, previous identities, and editable post-mortem reports for missed rounds.
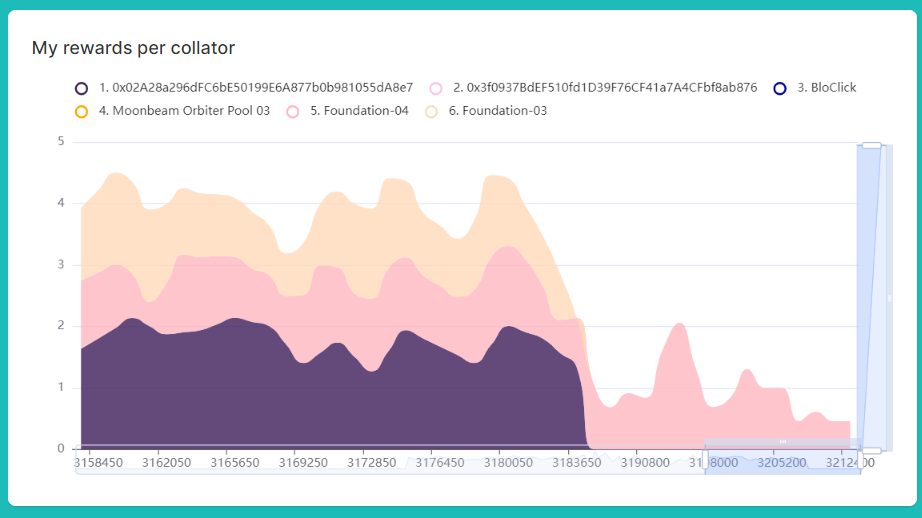
Personal dashboards will be completely redesigned for a more streamlined and user-friendly experience. Improvements will address current issues like long waiting times, lack of event navigation, fixed chart periods, no date filtering, and no real-time updates.
Advanced staking interface - enhanced functionality
While the current StakeGlmr does not offer staking extrinsics due to Moonbeam’s existing solution, the new version will promote diversification across multiple collators. Users will be able to choose their staking amount, allocation strategy, and collators to stake with in a single transaction. This will increase the stability of the active set and improve delegators’ undelegation flexibility.
Multiple wallet integration
The new platform will seamlessly support multiple wallets for both stakemovr and stakeglmr from the outset.
Cost-effective, robust, and speedy
While our current setup is durable, it’s expensive, costing $1,000 per month in cloud provisions. Additionally, due to DynamoDB stream limitations, errors must be resolved within 24 hours, or events are lost. The new configuration will be just as robust but more cost-effective, allowing indefinite retention of ETL errors.
To guarantee a durable and near-real-time API, we’ll deploy our services in two layers. The first, faster but less reliable layer, will have a dedicated server hosting all services (node, indexer, and ETL services) in a single unit. This server will mostly update DynamoDB tables and be responsible for catching up with the chain from its genesis.
The second layer will be cloud-based, utilizing microservices, cloud instances, cloud-based Postgres, and multiple RPC node providers. This layer will be activated daily for a short period (to catch up with the chain) or when layer 1 fails. By running this stack for only a fraction of the time, we’ll achieve durability and reliability at a much lower cost.
Both layers will utilize temporal.io to coordinate and ensure processes are completed and errors are addressed. Table updates will be detected by microservices and sent to connected clients via Lambdas and websockets, maintaining an auto-scalable push infrastructure.
Team Experience
Our team has a deep understanding of parachain staking pallet mechanics, which we’ve leveraged to consult other networks and create similar dashboards for them. We appreciate the needs of both collators and delegators and are committed to providing reliable, trustworthy data—especially important as more resources offer inconsistent information.
The project will involve two senior developers with extensive experience in various programming languages and cloud technology stacks. Ioannis will focus on backend development, while Abdullah will concentrate on frontend tasks and deployment pipelines, both bringing their expertise to all aspects of the project. We chose exclusively senior talent because the required stack is advanced and multidisciplinary, making junior talent more costly in the long run.
Value to the Moonbeam Ecosystem
Staking efficiency is crucial for network decentralization and security of a PoS network. Our new staking platform aims to simplify the user experience while promoting a healthier network.
The new Moonbeam staking website aims to provide a better user experience for stakers. Many stakers have found the current staking system complicated and have had issues with not receiving rewards. To address this, the new website will use pizza (yes, pizza!) as an example to explain how rewards are calculated, making it easier for users to understand.
In addition, the new website will allow users to stake with multiple collators in one move, reducing their risk of not receiving rewards due to a dropped-out collator. The website will also enable account login from the home page, allowing for custom advice on the minimum stake and currently staked, to avoid going below the minimum bond.
By improving the user experience, the hope is to gradually increase the total percentage staked. By spreading delegations among multiple collators, the stability of the active set will increase, thereby reducing the volatility of funds staked and improving overall security. Finally, decreased use frustration should enhance the perceived value of Moonbeam and promote growth.
Total Cost and Deliverables
Milestones
We anticipate deploying a production ready version to Moonriver and Moonbeam in 4 months. We have divided the project to two, 2-month milestones:
M1, 2 months
- SvelteKit frontend app, with mock db calls
- Inegration of app with wallets, chain queries, and extrinsic calls
- Indexing backend and ETL services
M2, 4 months
- Additional microservices
- Full frontend + backend integration
- Testing
- Deployment to production
Team
Ioannis T. - Senior backend developer and cloud architect
Abdullah C. - Senior frontend developer and deployment specialist
Cost
Our two senior developers each working 20 hours per week. At a rate of $70 per hour, the total cost comes to $44,800. Requested amount is going to be divided between Moonbeam and Moonriver treasury in 80-20 ratio (respectfully):
Moonbeam part (total for M1 and M2): $35,840:
100,397.91 GLMR, based on MA(30): GLMR: 0.35697954 (Coinmarketcap)
This proposal concerns only M1, which is 50% of the total, that is 50,198.95 GLMR
Moonriver part (total for M1 and M2): $8,960:
1,135.65 MOVR, based on MA(30): MOVR: 7.889724578 (Coinmarketcap)
This proposal concerns only M1, which is 50% of the total, that is 567.82 MOVR
Use of Treasury Funds
The treasury funds would be used for paying out to Skinny Bottle Ltd company for development expenses. The proposal execution will be started if the proposal is approved.
This proposal covers both M1 and M2 expenses that are required to deliver a fully functional, production-ready product.
We propose two payments: 50% of the GLMR and MOVR total amounts upfront for M1, and, after the delivery of M1, 50% upfront for M2.
Technical Specifications
StakeBaby will use the following stack to implement and deploy the projects.
SubSquid for indexing and processing ETL jobs
After testing SubSquid, we found it to be a highly reliable and efficient solution for indexing both Substrate and EVM data.
Temporal.io for orchestrating indexing and ETL jobs
Our tests with Temporal and SubSquid revealed that they effectively address most challenges associated with orchestrating indexing and ETL workflows, allowing us to concentrate on value-driven logic now and in the future.
AWS DynamoDB for user-requested transformed data
We currently use DynamoDB, which performs well. The new design will have both Lambdas and SvelteKit directly query DynamoDB, as opposed to just Lambdas.
Postgres for storing raw indexed data
SubSquid’s default choice, Postgres works well for storing raw data that doesn’t require frequent access or concurrent user requests.
AWS Lambda
AWS Lambda for scalable, independent microservices or those needing to run for longer than 3 seconds.
SvelteKit frontend application framework + Vercel for deployment
SvelteKit enables server-rendered pages and SPA functionality, reducing the number of managed microservices, simplifying deployment, and enhancing SEO.
NodeJS and Go for the backend
NodeJS will be our default language, with Go used in cases where high concurrency is needed (e.g., pushing to websockets).
Thank you for your attention and please let us know if you have any questsions/suggestions.