thanks for the update!
1 Like
Really looking forward for the rocket-launch ![]()
1 Like
Update on progress.
Frontend - 100% of HTML done, 70% converted to Sveltekit
Backend
Currently redesigning the parachainStaking pallet indexer to make it more generic so that we can quickly use the same logic to cover other pallets or other networks. The new design is based on a DAG manager that runs queries as soon as their input dependencies are ready (outputs of queries are inputs to other queries).
Lines of code without comments:
Frontend Sveltekit App
8252 Svelte (HTML + Typescript)
3008 Typescript
Indexer
5425 Typescript
1071 Golang
We are pretty late on our first milestone, but I am sure that the end product will justify the extra wait!
4 Likes
Thanks for the update, sounds like it’s really coming along.
1 Like
When beta sneak peek? ![]()
![]()
2 Likes
Thanks for the update, jaja yeah if is possible see some imgs of the frontend ![]()
1 Like
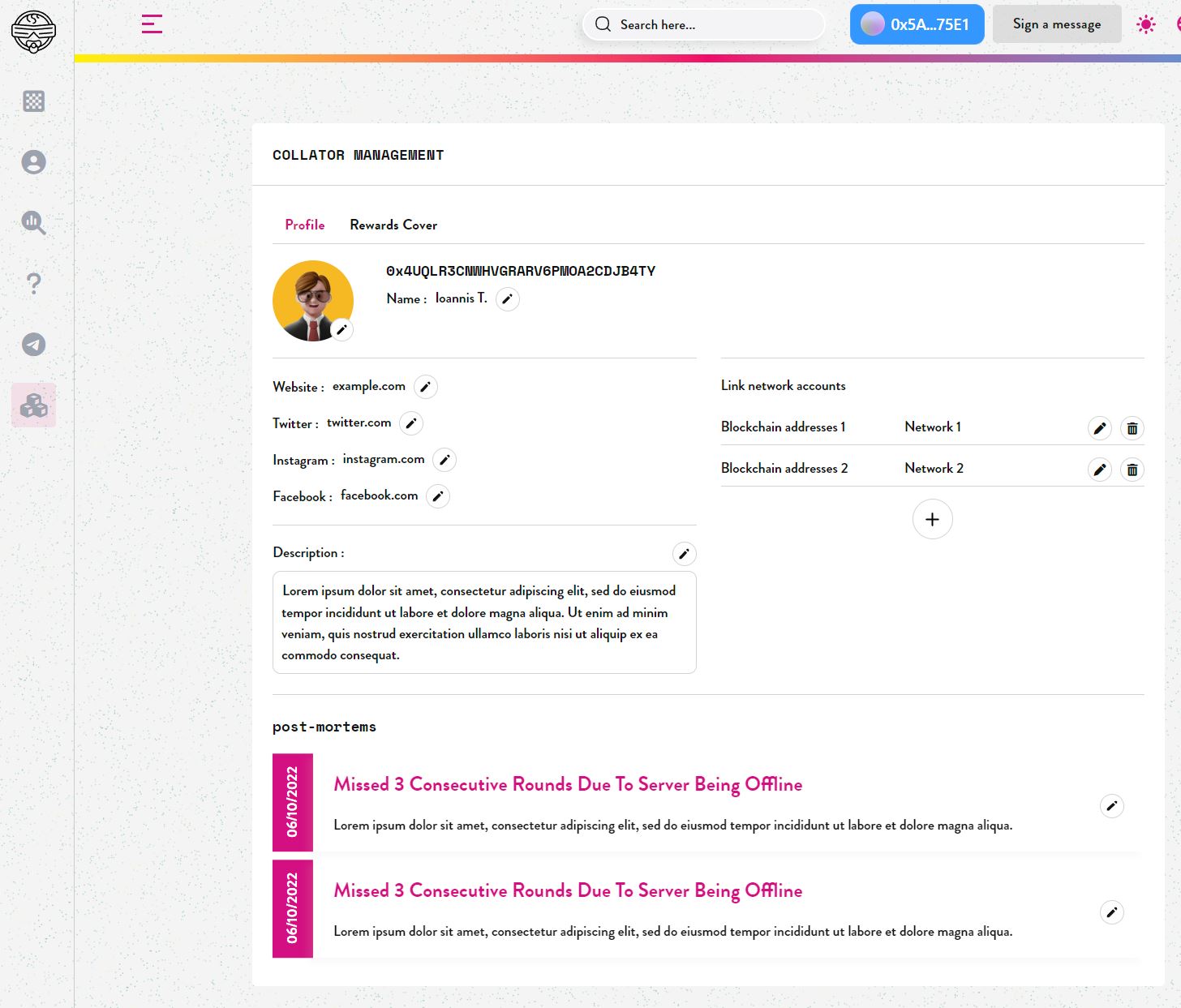
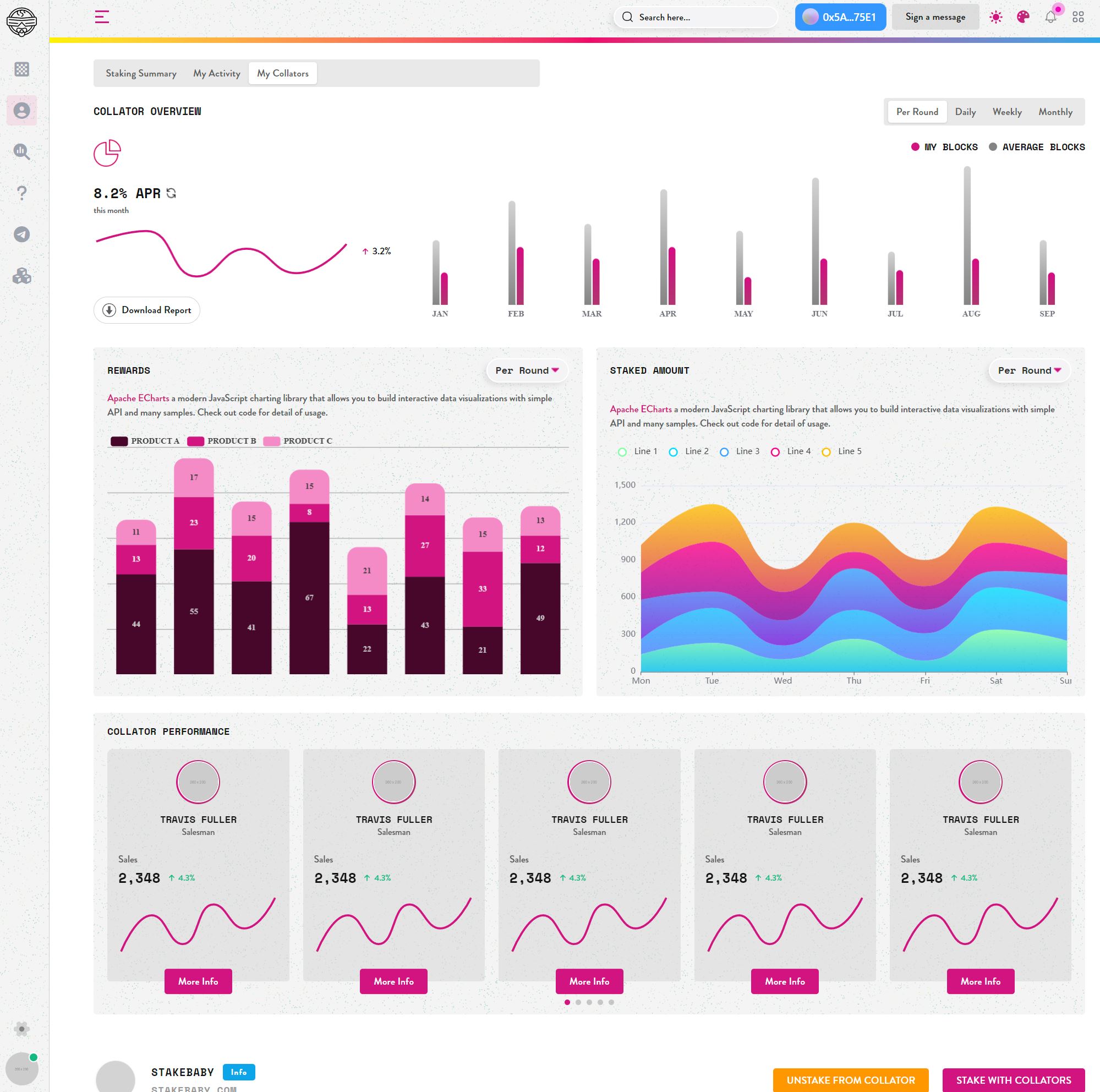
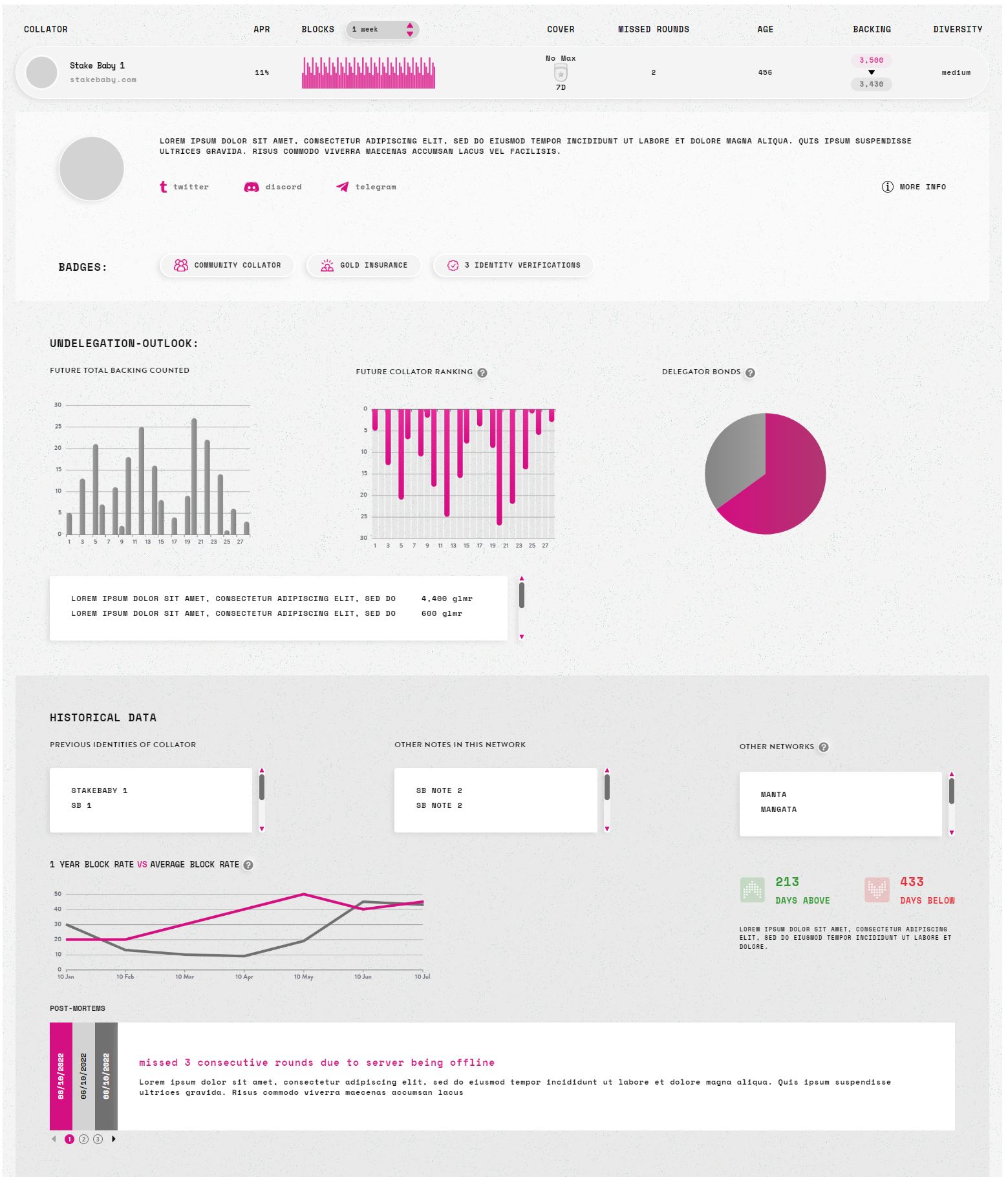
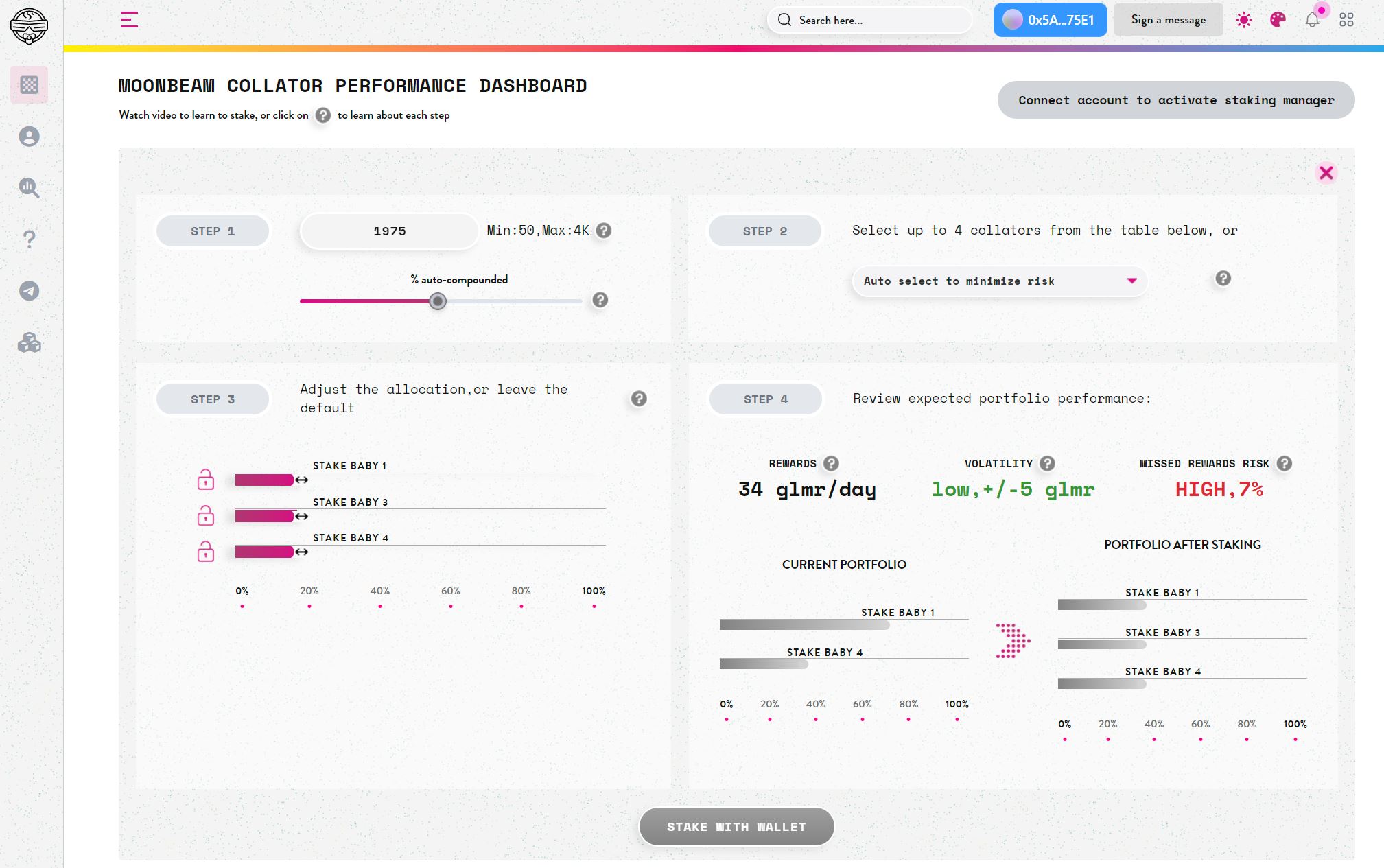
7 Likes
I think we will be ready to share towards the end of September. Going to an island for 20 days now with family so i won’t be able to do much in August but I will do my best to steal time here and there ![]()
5 Likes
Wow, this looks great! And seems that it will lead to more big bags spreading there stake over more collators, which is better for stakers and collators. Bravo!
2 Likes
That looks great sir, have dark mode?
I will be possible to see my staking rewards ( accumulative) in a period of time ( that i choose ? ( Like the last 55 days, 7 days , 30 days, etc?)
1 Like
Yes and yes. All dashboard timeseries are in rounds, days, weeks, and months and all blocks are reflected in the records within 4-8 seconds.
3 Likes
Great sir, waiting for it
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.
Apologies for the long silence! Just wanted to let you know that our github commits keep coming and we can’t wait to share the results! Long wait will pay off ![]()
5 Likes
Hey sir @stakebaby can you provide an update about this?
Sure!
I have finished the indexer that is responsible for building the database. This goes well beyond staking data and includes almost everything. The resulting database has timeseries for all querable data (per account too). It;s actually more of a timeseries graph database, so all related entities are connected.
The app will allow you to query this data through a chtgpt-like interface. Of course, there will also be the staking interface as promised (the indexer for that was finished 2 months ago).
I am taking some time to fine-tune and test the current indexer because, even as fine-tuned as it is now, it will take 1 month to index the entire chain. It’s a pretty intensive process and I want to make sure it’s as efficient as possible.
good thanks for your update, I imagine it must not be easy yes jaja
Can you give us some use cases where this new indexer will be used, what can the user do with it?
However, you have a rought timeline, where is the new page fully operational?
The database has all events (like any normal indexer like subscan) PLUS time/block snapshots of values (balances, counts, points, constants, address sets, everything…). The entire database is sparse (ie… values are recorded only when they change) or the data size would explode. In current simulations, the final size will be short of 1TB. This also includes the graph edges that allow querying by any user or contract address.
The idea is to allow querying anything, even complicated queries that would require JOINS. We are using surrealdb which has a very efficient and user-friendly replacement for JOINs. So, things like, “give me the total staked amount of all users that voted for referendum X” will be possible in SurrealQL (an SQL variant), but it remains to be seen how well the AI will translate the user query to it. It’s a multi-step process that requires database context (drawn from a vector DB), SurrealQL fine-tuning (one-time process), and prompt design. We will get there eventually.
For fully operational, it will have to be Q1 2024, but i want to deliver the private demo before year end.
4 Likes
Hi Ioannis!!!
Quick one: can you update us about current status on this program?
As you can imagine I am asking because we love your current tool and we’re strongly lookimg forward the 2.0 version!!!
Thanks a lot in advance!
Michele
1 Like